前回は、ZYBOのPmod JEをたたくドライバに載っているアドレスからリファレンスマニュアルを調べようとしたけど失敗した、というところまでだった。
ならば、正攻法で調べるしかあるまい。
Pmod JEからたどっていくのだ。

7本使っているが、1本見ればよかろう。

これはIC19Bなのだが、IC19AがZynqだから、これもZynqのピンなのだろう。
V12は、IO_L4P_TO_34という名称なのか。
これで検索して出てくればよかったのだが、それっぽいものが出てこない。
テクニカルマニュアルj_ug585-Zynq-7000-TRM.pdfの「2.8 PL I/Oピン」に載っているT[3:0]がそれか?

T0だから、メモリバイトグループT0に属するメモリバイトグループということか。
同じ表の中に、こういうのもあった。

IO_L3N_だから、こっちの可能性もある。
詳細は「パッケージおよびピン配置ガイド(pdf)」を参照とのこと。
別ドキュメントかー。
Zyboに搭載されているのは、ZYNQ XC7Z010-1CLG400C。

SIOとPS I/Oに大別されている。
PS I/OはPS側から制御するI/Oだろうから、SIOはPL側から制御するのかと思ったが、SIOは「SelectIOリソース」という意味らしいので、PSかPLかを選択できるのかもしれん。
ネットで検索すると、「7シリーズ FPGA SelectIOリソース ユーザーガイド」というPDFが出てきた。
7シリーズはZynqのPL部だから、PL部なのだろう。
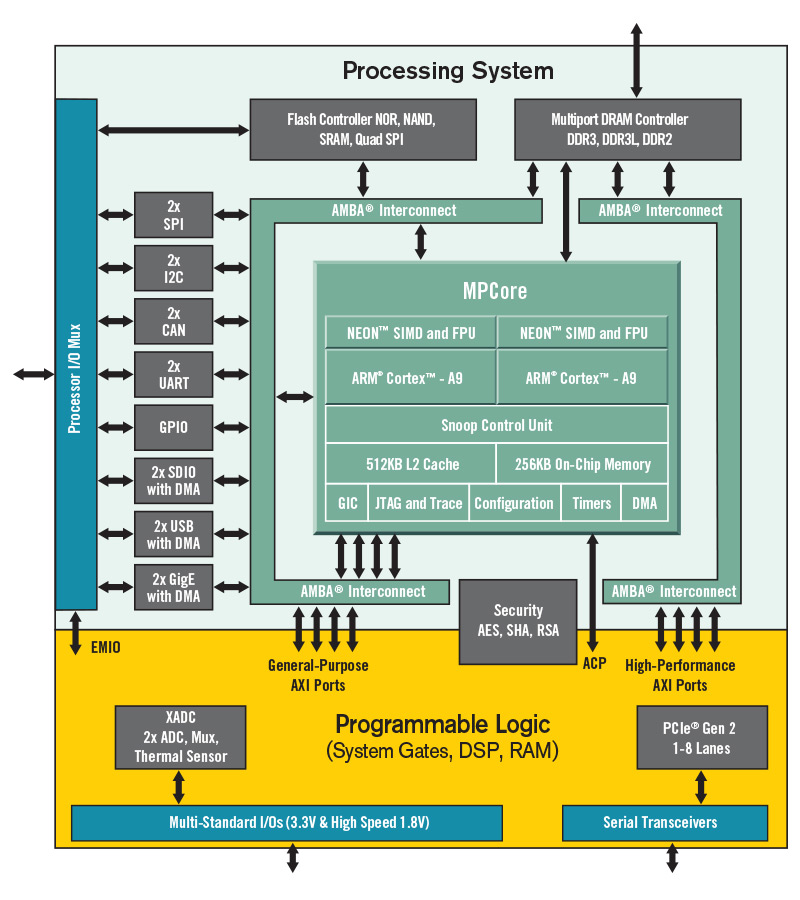
Zynqの概略図でも、PL部に"Multi Standards I/Os"というものがあるし。
https://japan.xilinx.com/content/dam/xilinx/imgs/block-diagrams/zynq-mp-core-dual.png
IO_L4P_T0_34という名前だが、こういう意味になると思われる。
- IO : ユーザーI/Oピン
- L : 差動ペア
- 4 : バンク固有のペア
- P : 差動ペアの正側
- T0 : メモリバイトグループT0に属する
- 34 : バンク番号
さっぱりわかりません。。。
まず、バンクの説明図があった。
PLバンクの図らしい。

「すべてのHP I/Oバンクは完全にボンディングされていて、すべてのPSバンクは完全にボンディングされている」らしい。
HPと書いてあるけど、表ではHPが0本、HRが100本だったから、HR I/Oバンクだと思う。
- HR : Hight Rangeバンクのことで、3.3V対応という意味のようだ
- HP : Hight Performanceバンクのことで、1.8V対応という意味のようだ
Vivadoでも1.8Vを3.3Vに変更していたが、こういう意味があったのか。
ピン配置はASCIIファイルになっているらしい。
XC7Z010のCLG400はこれ。
うん、V12はIO_L4P_T0_34で、メモリバイトグループ0、バンク34だね。
そして、I/Oタイプは「HR」とのこと。
さっきの図でBank 34 HRとなっていたから、そのままなのかな。
あとは、ピン配置の図と、ハンダ付けとかそういう説明があったが、今回はよかろう。
ピンの数は、20x20 = 400本のようだ。
わからなかった用語を検索しておく。
差動って、USBとかで使われている正負が逆転したやつだろうか?
それとも、差動増幅というやつだろうか。
なんとなく、前者っぽい。
https://ja.wikipedia.org/wiki/%E5%B7%AE%E5%8B%95%E4%BF%A1%E5%8F%B7#.E9.AB.98.E5.91.A8.E6.B3.A2IC.E3.81.AB.E3.81.8A.E3.81.91.E3.82.8B.E5.B9.B3.E8.A1.A1.E6.8E.A5.E7.B6.9A
というわけで、アドレスについては書いてなかった。
次はデバイスツリーを見る。
これにはアドレスが書いてあったはずなので、そこからたどれるかもしれん。
というより、アドレスを直接ドライバに書くのではなく、最終的にはデバイスツリーから取ってくるようにせんといかんのか。
0x41200000だが、ZynqではなくARMの方(plnx_arm-system.dts)に出てきた。
そっちか!
gpio@41200000 {
#gpio-cells = <0x2>;
compatible = "xlnx,xps-gpio-1.00.a";
gpio-controller;
reg = <0x41200000 0x10000>;
xlnx,all-inputs = <0x1>;
xlnx,all-inputs-2 = <0x0>;
xlnx,all-outputs = <0x0>;
xlnx,all-outputs-2 = <0x0>;
xlnx,dout-default = <0x0>;
xlnx,dout-default-2 = <0x0>;
xlnx,gpio-width = <0x4>;
xlnx,gpio2-width = <0x20>;
xlnx,interrupt-present = <0x0>;
xlnx,is-dual = <0x0>;
xlnx,tri-default = <0xffffffff>;
xlnx,tri-default-2 = <0xffffffff>;
};ARMの方ではあるが、xlnxとなっているところが多いから、たぶんXilinxがカスタマイズしたのかな。
Zynqの概略PNGを見ると、PS部とPL部の接点は多くなかった。
そういえば、ZynqにAXI GPIOを追加したな。

今回のInterface誌に載っていた手順を振り返ると、こうだった。
- Vivadoで新規プロジェクトを作る
- AXI GPIOを追加する(Zyboのテンプレートを使ったので、ボード上のLEDにつながっていた)
- GPIOのブロックを変更して、4bitを7bitにする
- XDCファイルを変更して、ボード上のLEDからV12などに変更する
元々はボード上のLEDを制御するGPIOだったのだ。
だから、V12が0x41200000に割り振られているのではなく、AXI GPIOでアクセスする先頭が0x41200000で、AXI GPIOのつなぎ先をV12に変更した、というだけのことか。
いつものマイコンだと、ピンと機能が結びついていて、どの機能を有効にするかを設定する、というやり方だった。
FPGAでは、ある程度はピンの使い道を変更できるということだな。
「今回はUARTを2本使いたいけど、そうするとSPIが使えなくなるから、UARTの代わりに空いているI2CにしてFTDIのチップ載せるか」みたいなことはせず「今回はI2C使わないからUART2本とSPIに割り当てよう」ということができるのだ。
というわけで、Pmod JE --- AXI GPIO、というつながりで考えればよさそうだ。
では、Pmod JEのV12がAXI GPIOにつながっているとしよう。
次は、AXI GPIOがARMのGPIOにつながっていることを確認したい。
AXIバスだから、このルートだろう。

AXIバスはARMのAMBAバスにつながっているようだ。
AMBA Interconnect、というらしい。

インターコネクトは、Zynqテクニカルマニュアルの5章だ。
PSから書込みたいので、M_AXI_GPxになるのかな?

「Zynq-7000 All Programmable SoC Data Sheet」の最後の方にメモリマップがあった。
http://www.xilinx.com/support/documentation/data_sheets/ds190-Zynq-7000-Overview.pdf

0x4000_0000がPL AXI slave port #0なので、PSがマスター=M_AXI_GP0という認識と一致した。
「5.6.1章 AXI信号」に表があって、「読み出しアドレス」「書込みアドレス」などあるのだが、アドレスっぽい値が書かれていない。
変換できるのかもしれんが、ちょっと私には無理だな。。。
0x4000_0000 + 0x0120_0000、という計算だと思う。
この0x0120_0000というオフセットの計算方法が知りたいのだ。
デバイスツリーでは、0x4120_0000, 0x4121_0000, 0x4122_0000の3つがあるので、何かあると思うのだが・・・。
ZYNQのPS/PL通信をやってみた(4) GPIOテストコードを書く: なひたふJTAG日記
最初のステップでXPSで生成したAXI_GPIOを操作したいけどアドレスがどこにあるか・・・とかそういうことを調べる必要はありません。それらはxparameters.hをインクルードすることで解決されます。
なんですってー!
PetaLinuxのディレクトリ内をfindした。
$ find ./ -name xparameters.h
./tools/hsm/data/embeddedsw/ThirdParty/sw_services/openamp_v1_1/src/open-amp/obsolete/system/generic/machine/zynqmp_r5/xil_standalone_lib/xparameters.h
./tools/hsm/data/embeddedsw/XilinxProcessorIPLib/drivers/common_v1_00_a/src/xparameters.h
ファイルはあったのだが、4年も経過したからか、該当するマクロ名はなかった。
XPSじゃないしね。
しかし、ネットで検索していると、xparameters.hを使っている人が多い。
そして、XPAR_LED_xxxみたいなものもあるので、これは自動生成する類のものと思われる。
GPIOをソフトウェアから制御する | 特殊電子回路
Vivadoでプロジェクトを立ち上げ、Launch SDKして、Newで"Application Project"を選び、Hello Worldを選んだ。
そうすると、なにやらbspというプロジェクトもできている。
その中を見ていくと大量のincludeファイルがあり、xparameters.hもあった。

あー、こうやってアドレスがわかるのね。。。
あまり納得できたわけではないのだが、今回はこれでもいい気がしてきたので、これで話を進めよう。


{kind=link}